Biography
João Santos is a Senior Data Engineer at Transporeon, a leading logistics platform revolutionizing supply chain operations. Previously, he worked as a Senior BI Engineer for the EU Supply Chain Analytics Team at Amazon, the world’s largest online marketplace and cloud computing platform.
Expert in Data Engineering (Batch ETL/ ELT Pipelines and Modeling, Data Lake/ Warehousing, Orchestration, Quality/ Testing), Amazon Web Services (AWS) (Data Architecture, DevOps, Serverless, Linux/ Unix) and Business Intelligence (Data Preprocessing, Dashboarding, Reporting, Monitoring)
Highlighted Courses: Process Strategy and Optimization; Process Dynamics and Control; Oil Refining and Petrochemistry; Industrial Informatics II; Entrepreneurship and Innovation; Engineering Project.
Highlighted Certifications & MOOC: AWS Certified Cloud Practitioner; Data Analyst with SQL Server by DataCamp; Complete Data Science Bootcamp 2020 by 365 Data Science; Process Mining Expert by Celonis.
- Cloud Computing (AWS)
- Data Engineering
- Microservices
- Process Optimization
- Data Visualization
MEng in Chemical Engineering - Processes and Product, 2020
Faculty of Engineering of the University of Porto
BSc in Engineering Sciences - Chemical Engineering, 2018
Faculty of Engineering of the University of Porto
Personality
Myers–Briggs Type Indicator (MBTI)
Assertive Architects are Introverted, Intuitive, Thinking, Judging and Assertive. These thoughtful tacticians love perfecting the details of life, applying creativity and rationality.
Analysts embrace rationality and impartiality, excelling in intellectual debates and scientific or technological fields. They are fiercely independent, open-minded, and strong-willed.
Confident Individualists prefer doing things alone, choosing to rely on their own skills and instincts instead of seeking contact with other people. They know what they are good at.
Experience
EU Supply Chain Analytics FC Launch
The EU SC FC Launch Team manages the supply chain ramp up of new Amazon-owned FCs from zero to one. The team strives to support the overall S-Team goal of 10% YoY productivity improvement of new FCs by providing required IB and OB daily/weekly volumes to maximize new FC's operation effciency.
- EU SC Network Planning MBR Tech Lead
Led the EU SC Network Planning Tech MBR, coordinating 5 subteams across 25 tech projects. Collaborated closely with 5 tech members and 5 business stakeholders, orchestrating the successful delivery of solutions.
Details
Internal Documentation- The Network Planning Tech Projects MBR serves as a bridge between technical advancements and business strategy, providing an accessible overview for all stakeholders. Weekly calls help align tech priorities across subteams and BIE resources.
- Project management is facilitated using Asana, ensuring tasks are well-structured, tracked, and completed on time. Subteams are assigned clear priorities and deadlines, and project progress is monitored to ensure alignment with strategic goals.
- Consult on the design, implementation, and delivery of BI solutions in complex problem spaces, delivering critical-path code and guiding teams on key trade-offs, ensuring that solutions are as simple and scalable as possible.
- Enable BIEs and interns to contribute meaningfully by promoting teamwork and showcasing their innovations, fostering a collaborative and innovative environment.
- Rolled out EXTREME: Excel to Redshift Migration Engine to EU Central Flow
Successfully implemented EXTREME for over 20,000 EU Central Flow users, streamlining the migration of Excel data to Redshift.
Details
Internal Documentation- Utilizes an IAM role instead of a generic user for querying Redshift, enhancing security and access control.
- Averages around 10 daily service calls, demonstrating high usage and integration within existing workflows.
- Over 100 local tables created, significantly improving data accessibility and reporting capabilities for users.
- Based on user feedback, EXTREME has reduced the time required to manually update a local table via traditional SQL commands by more than half.
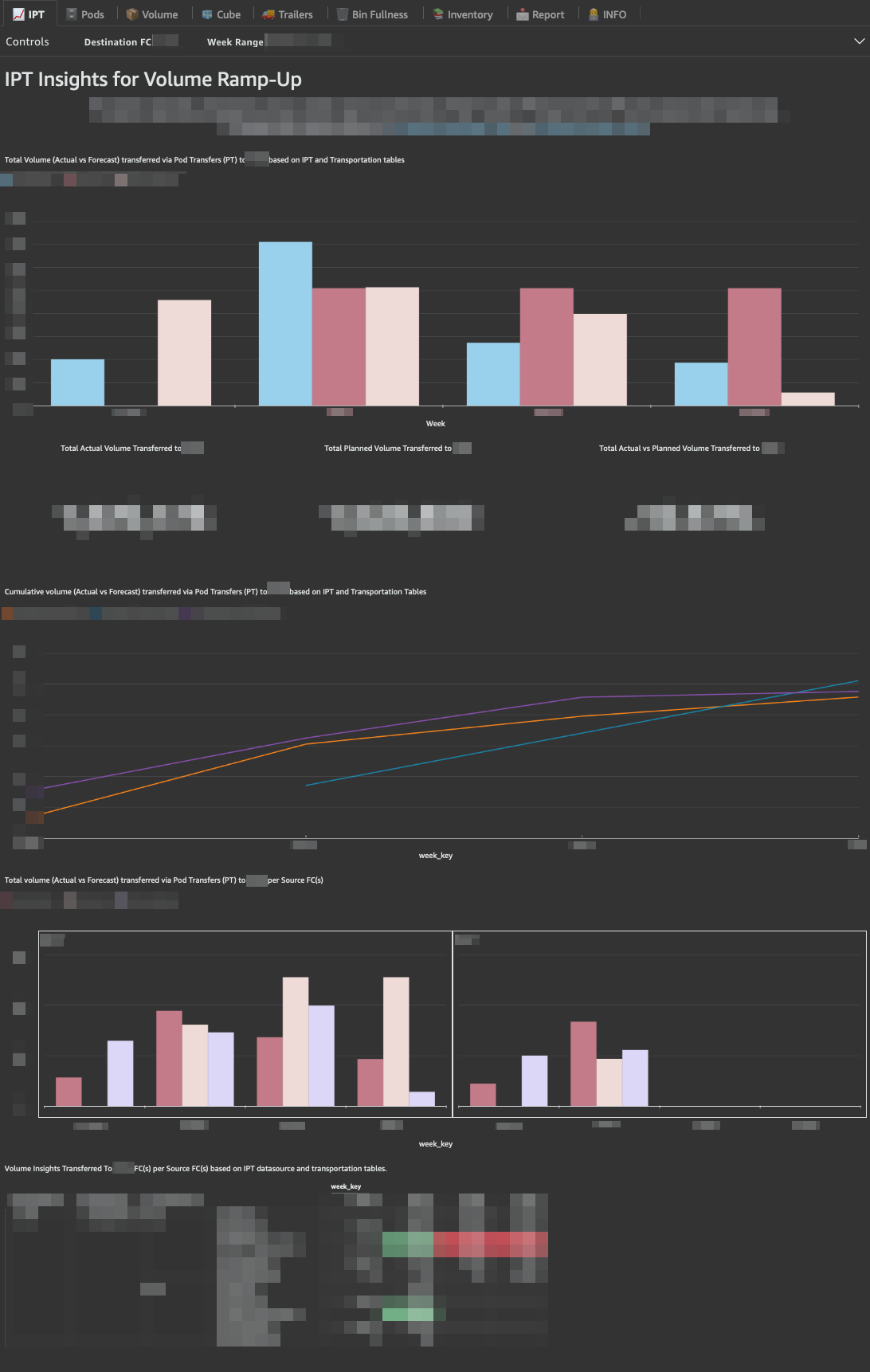
- Developed EU/NA Pod Transfer QuickSight Dashboard
Launched two comprehensive dashboards to track pod transfers across EU and NA warehouses, leveraging 6 QuickSight datasets per region while denormalizing data from Amazon's central S3 datalake (Andes).
Details
Internal EU Dashboard | Internal NA Dashboard- Data pipelines denormalized using Spark SQL, forming Redshift tables to ensure seamless data availability for key metrics and insights.
- Dashboard metrics cover pod transfer volumes, item quantities, warehouse fullness, and relative fullness, viewed over 600 times by 40 distinct users.
- Includes 8 tabs (📈 IPT, Pods, Volume, Cube, Trailers, Bin Fullness, Inventory, and Report), with filters for warehouse selection and date ranges and finally a tab dedicated to our team contact information and extract/ load job details (👨💻 INFO).
- QuickSight Dataset Optimization and Redshift Usage Reduction
Implemented a data-driven approach to identify and deschedule QuickSight datasets feeding unused or underutilized dashboards, improving Redshift query performance.
Details
Internal Documentation- Developed a process using CloudTrail logs and Redshift query metrics to track dataset usage, linking datasets to active dashboards and analyses.
- Reduced operational overhead by targeting datasets feeding dashboards with zero or minimal user views, freeing up Redshift resources and improving overall query performance.
- Partnered with Python integration to automate analysis and reconciliation of datasets with Redshift queries, views, and deleted dashboard events.
- Identified 50+ datasets that ran unnecessary queries, consuming 6+ hours of Redshift processing time weekly.
EU Supply Chain Analytics Data Engineering Admin
The EU SC Analytics Data Engineering Admin Team mission is to empower the users (+300 users) to produce and obtain data in the fastest, easiest and cheapest way, while maintaining and continuously improve the data infrastructure.
Ownership and management of 2 AWS accounts, including 2 Redshift clusters.
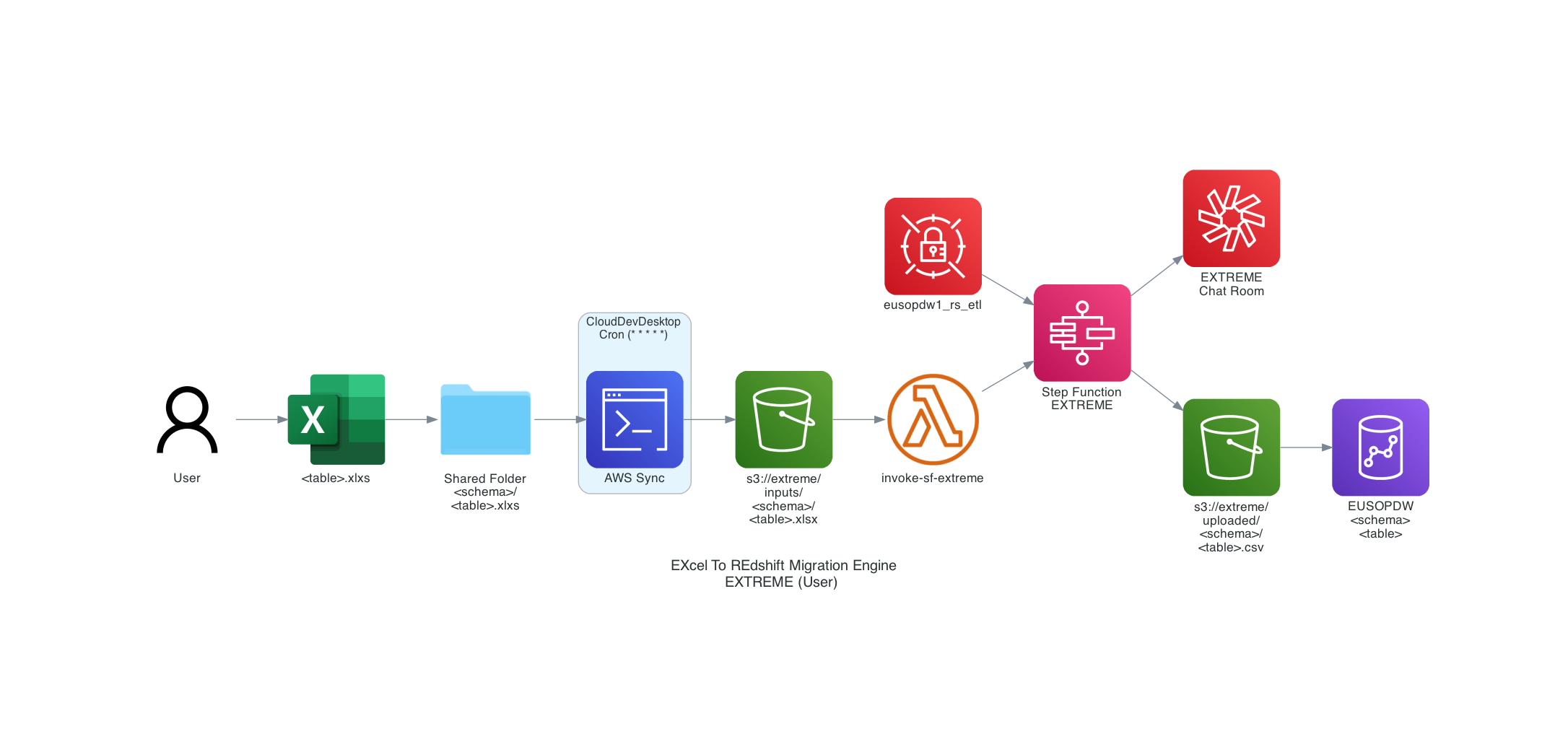
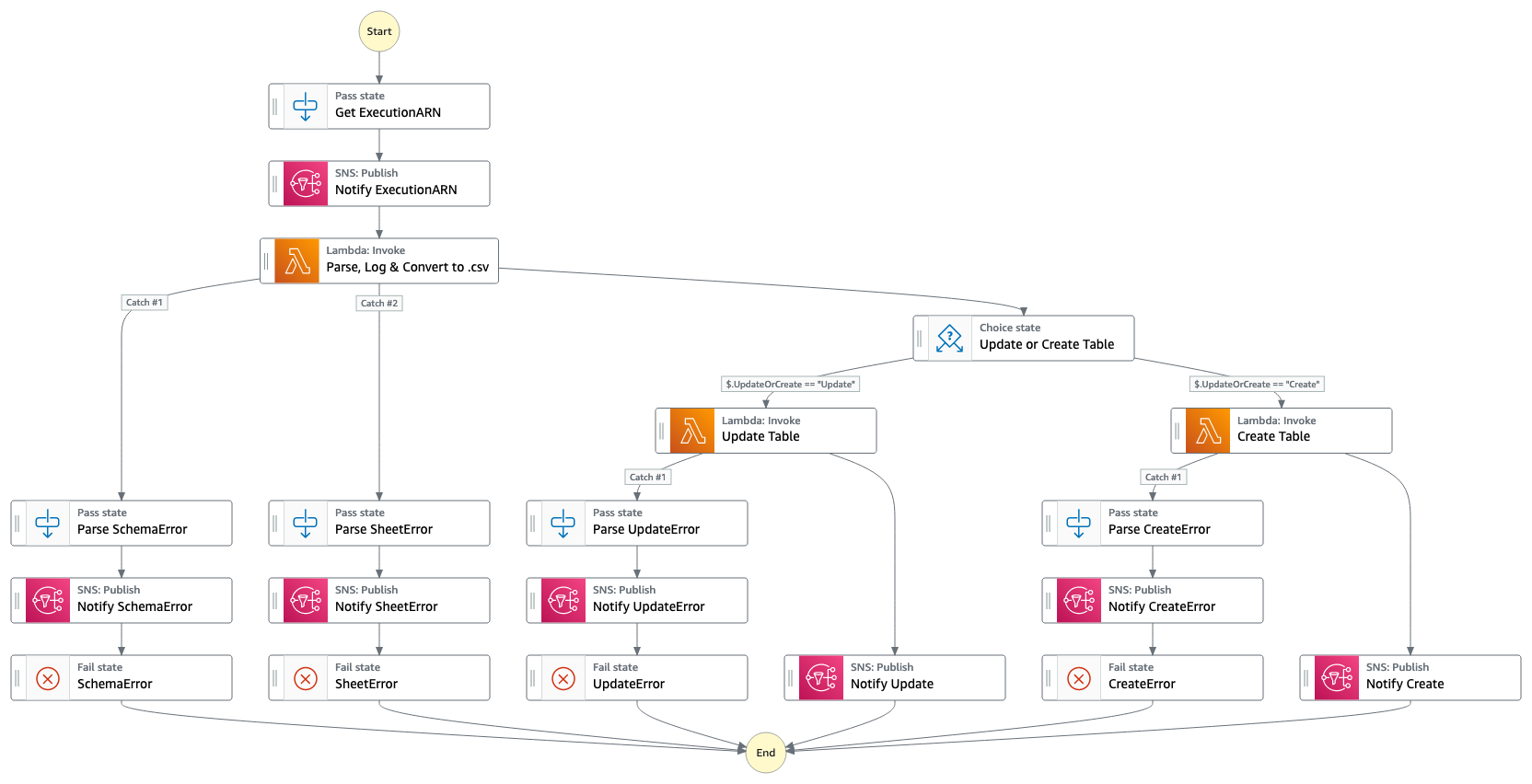
- EXTREME: Excel to Redshift Migration Engine
A Native AWS solution that automatically converts your .xlsx files into Redshift local tables seamlessly and quickly while additionally inferring the most frugal table definition based on the present data.
Details
Internal Documentation- EXTREME is centered around a micro-service orchestration workflow using AWS Step Functions. It was designed for the best user-experience by only requiring minimal knowledge on basic tools and functionalities using Excel and Network Shared Folders. Drop your Excel file inside the appropriate sub folder, wait and get notified on the EXTREME Chime room once the table has been Created or Updated on EUSOPDW.
- AWS EUSOPDW CloudWatch Dashboard
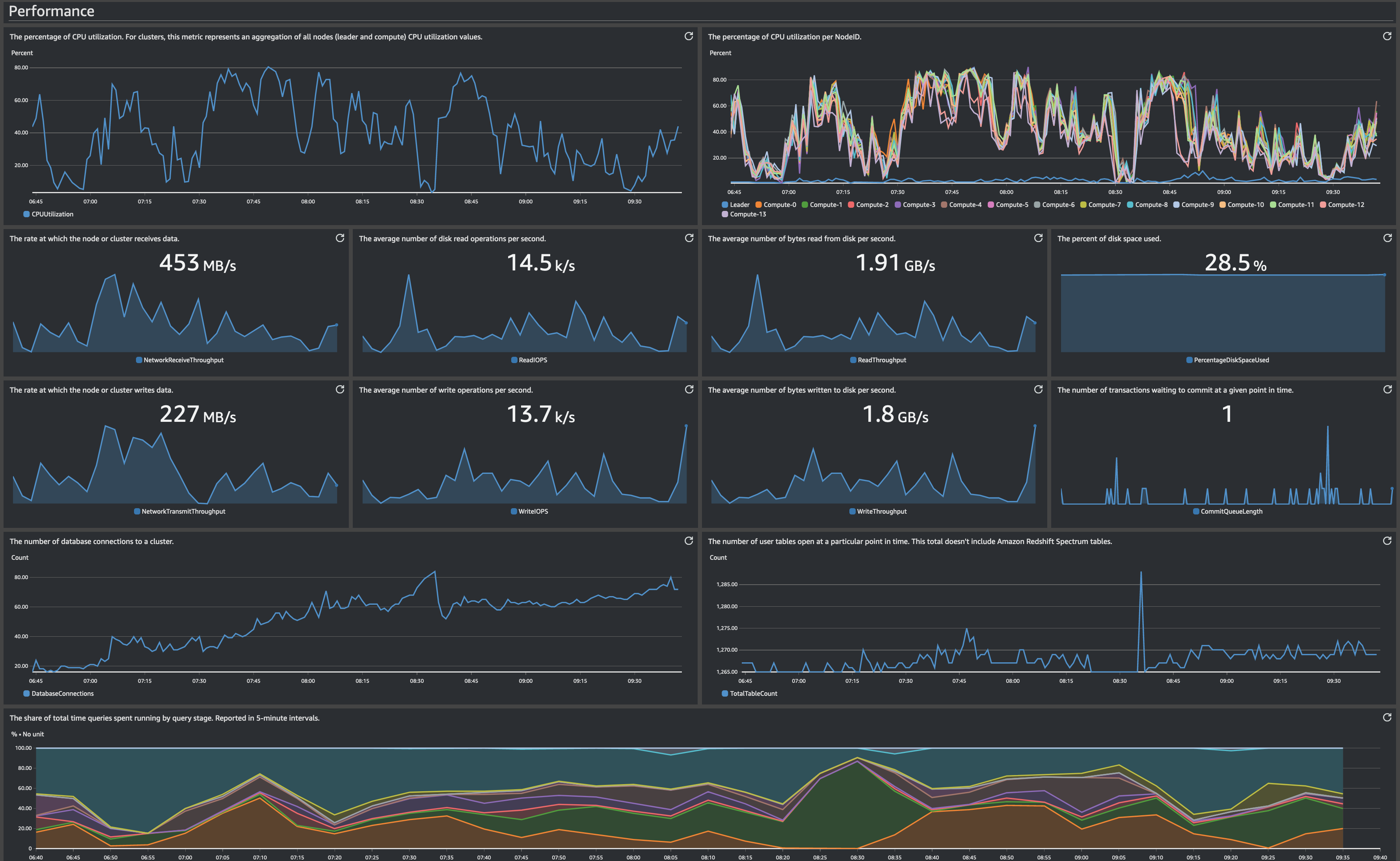
Leverage the power of CloudWatch metrics into EUSOPDW Redshift cluster to develop the EUSOPDW CloudWatch Dashboard. Using CloudWatch metrics for Amazon Redshift, we can get information about the cluster's health and performance up to the node level.
Details
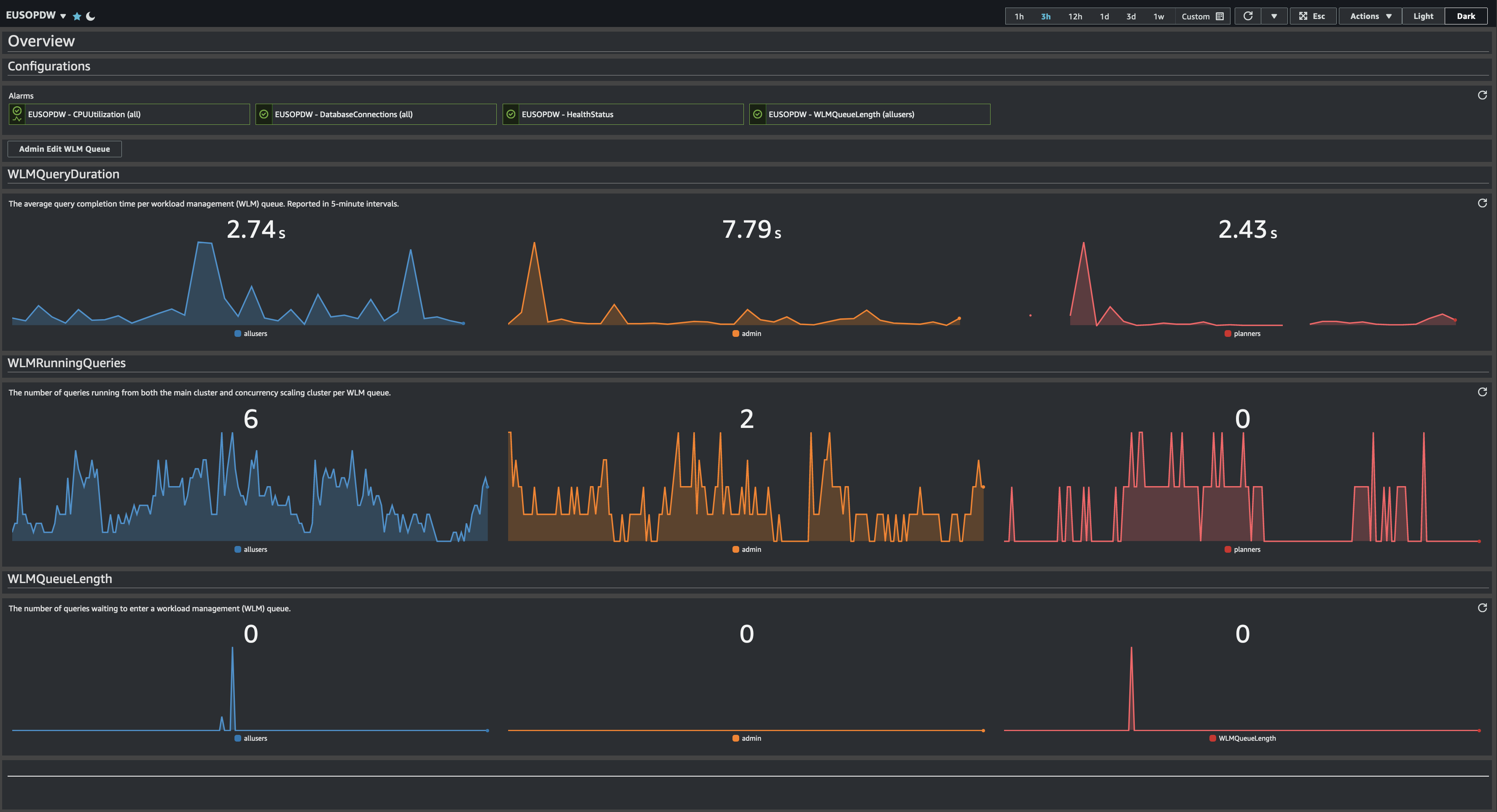
Internal Dashboard- EUSOPDW CloudWatch Dashboard monitors the real time performance of EUSOPDW cluster across multiple metrics, e.g. the average query completion time, the number of queries running or the number of queries waiting.
- The EU SC Analytics BI Admin Team have also implemented 4 metric alarms in order to proactively act on cluster issues, e.g. high backlog or unusual CPU utilization.
- The Dashboard is divided into 3 main section: 1 – Overview: Focus on 3 main metrics (WLMQueryDuration, WLMRunningQueries and WLMQueueLength) on the 3 main WLM Queues (admin, allusers and planners); 2 – Performance: Focus mainly on CPU utilization per node, network and I/O rates, open DB connections and query stage share; 3 – WLM Performance and Latency Performance: Similar to the Overview section but with more metric details and all the existing WLM Queues and latency granularity (short, medium and long).
- AWS Auto Tag
“Tag Early, Tag, Often”. Automatically tagging resources greatly improves the ease of cost allocation and governance by the BI Admin Team. It is a challenge to get users to remember to and correctly label every AWS resource. Fundamentally they shouldn’t have to.
Details
Public Documentation- As soon as a user creates a resource supported by AutoTag (such as EC2 instances, IAM users, IAM roles, RDS instances, S3 buckets, EMR clusters, VPCs, etc), AutoTag will automatically apply up to 3 new tags: C (Resource Owner) + T (Resource Creation Datetime) + I (Resource Invoked by what other resource).
- AWS Auto Scheduler
Reduces operational costs by stopping resources that are not in use and starts resources when their capacity is needed. This solution can result in up to 70% cost savings on those instances that are only necessary during regular business hours (weekly utilization reduced from 168 hours to 50 hours).
Details
Public Documentation- Simply tag the key as “AutoSchedule” and associate the respective scheduler value (i.e. Key = “AutoSchedule”; Value = “1130-only-stop”);
- Schedule configurations are set using the AutoScheduler-ConfigTable on DynamoDB. A user can create a period (i.e. office-hours: starts at 09:00, ends at 17:00 during week days) and then create a schedule based on a single or multiple periods (i.e. using the previous office-hours period but adding the timezone: Europe/London);
- Configuration setup also allows for vertical scaling: scale up or down based on the instance requirements (i.e. scale up an instance to t2.micro during weekends and scale down to t2.nano during the week).
- AWS Sagemaker Auto Stop
Sagemaker is the second largest cost in our AWS accounts. This solution auto-shutdown both SageMaker Notebook and SageMaker Studio instances when they are idle for 1 hour.
Details
Public Documentation- A lifecycle configuration provides shell scripts that run either when a notebook instance is created or whenever it starts. The deployed lifecycle config will run the autostop.py module every 5 minutes on the backend;
- It will be making API calls to the Jupyter server and checking the kernel status for ‘idle’. ‘Idleness’ as defined by Jupyter team, means that no code is running (other activities such as opening a new notebook will also reset the idle timer).
EU Supply Chain Analytics FC Launch
The EU SC FC Launch Team manages the supply chain ramp up of new Amazon-owned FCs from zero to one. The team strives to support the overall S-Team goal of 10% YoY productivity improvement of new FCs by providing required IB and OB daily/weekly volumes to maximize new FC's operation effciency.
- Tech Project Manager & Mentor
Manage a team of 5+ BI interns by applying Agile project management methodologies (Scrum & Kanban) on Asana. Enforce software development good practices (git for version control, pyenv for Python version management and poetry for Python packaging and dependency management).
Details
Internal Documentation- Setup documentation and provide support for new tech users ramp-up;
- Mentor and enpower BI interns for a successful career and experience;
- Manage technical projects on Asana based on Project Managers (PM) requirements. Break down the problem statement, set-up tasks and assign relative priorities, due dates and estimated completion times. Code review the merge requests (MR), main branch merging and production deployment (CI/CD);
- Impose a standardised code-style, formatter and linter (XML for SQL and black and flake8 for IDE). Use of snake_case for functions and variables and PascalCase for classes. Use of Google Style for docstrings. TOML for configuration files to be read by humans, JSON for machines;
- Enforce data pipelines documentation and Pyramid (internal tool as a scalable way of tracking the status and tracing upstream pipelines) enabled alerts for proactive monitoring and management of production-ready team pipelines.
- Pod Selection Algorithm
Output a list of pods to transfer based on a set of inputs, business criteria (objective functions) and hard operational constrains. The objective functions currently set are: Cube (SUM volume [ft2] of each unit in a pod); Uniqueness (Count of distinct ASINs in a pod that are unique relative to their presence within their respective marketplace); Quantity (SUM units in a pod).
Details
Internal Repository | Internal Documentation- The core modeling started as a Nested Sorting optimization but migrated to a Integer Linear Programming (ILP) optimization using the FICO Xpress Solver. While the core mathematical concepts remain, as opposed to achieve a single optimal output, PSA uses a weights tunning approach for every new set of inputs simulating 1k+ data points for different weight and objective function combinations;
- While the previous production model (SPOCK) produced an overall weekly weighted average of 33 cube per pod (CPP), PSA generated 36 CPP (~10% improvement). Fullness of all pods transferred is on average 105% instead of 90%. Similarly, the actual weekly weighted average units per pod (UPP) was 550 while PSA’s UPP equaled 420 (~15% decrease), which reduces OB NWA because of less inventory units. PSA really stands out when it comes to unique inventory: SPOCK logic transferred 140k unique units, totaling 7% with respect to the total transferred units, while PSA transferred 45k, 2% versus the total transferred units (500bps reduction).
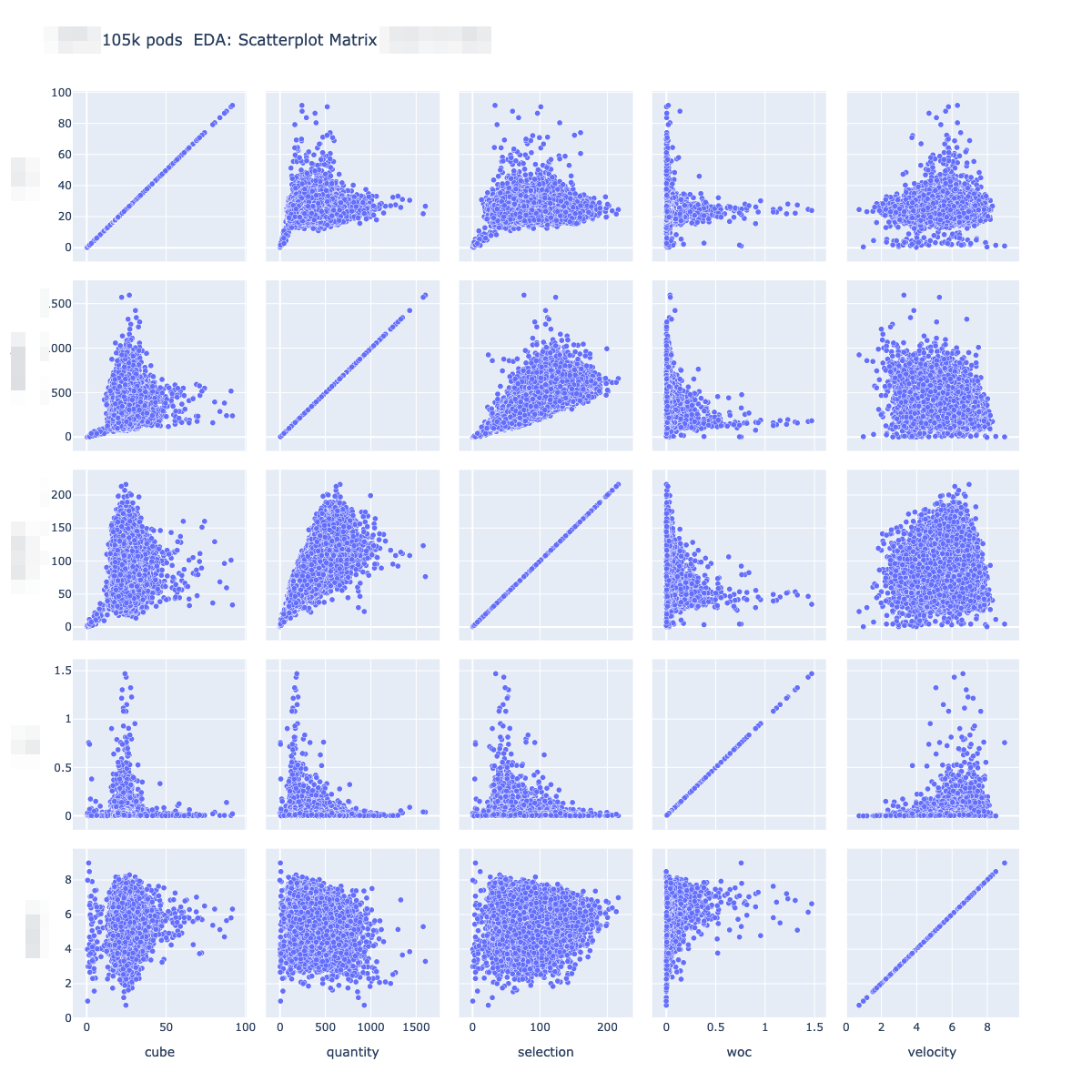
- Pre-Launch TSO Max Capacity Alert & Automated CPT Closure
Automated control on pre-launch TSO assigments for new FC launches. Gets live TSO from RODEO, updates a Chime room based on the predefined FC processing capacity threshold for a given source FC, destination FC and CPT and applies a RTCT Closure once 95% TSO capacity is breached.
Details
Internal Documentation- Pre-launch TSO is only available for unique inventory stranded in the new FC while outbound systems are still not live. It allows for a better customer promise but is highly risky as it directly impacts customer experience if the FC processing capacity vs TSO assignments per CPT is inadequate;
- There are 4 notification bins per CPT: 75-85%, 85-95%, 95-100% and +100%. The automated capping will trigger at +95%. In order to avoid triggering at every run, a log file is updated only triggering the alert once per bin;
- The script interacts with internal supply chain systems APIs to retrieve current arc assignments ready to be picked and arc scheduling and configurations in order to cap the CPT. Deployed on a EC2/ Amazon Linux 2 CloudDevDesktop and scheduled using cron (*/5 * * * *).
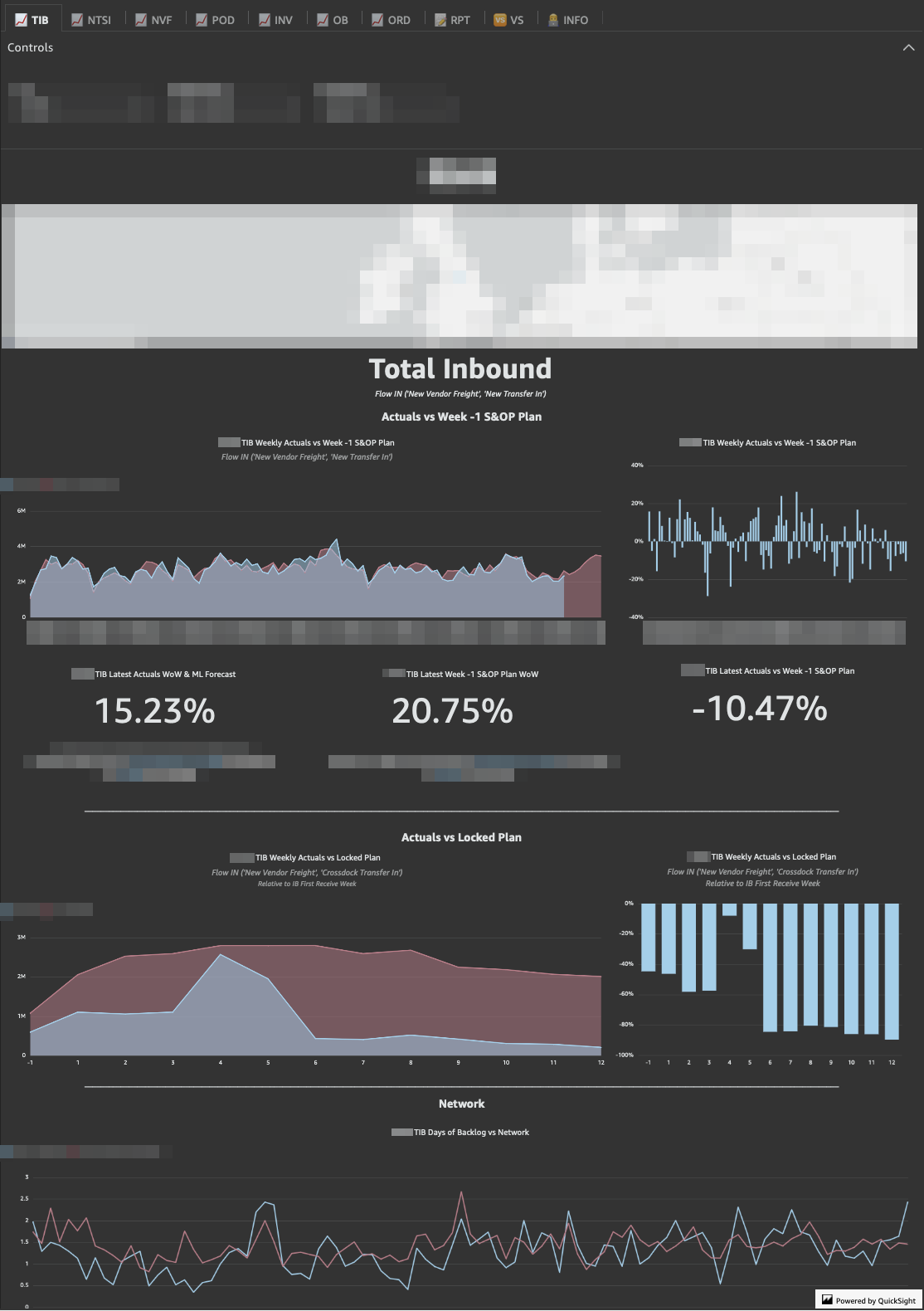
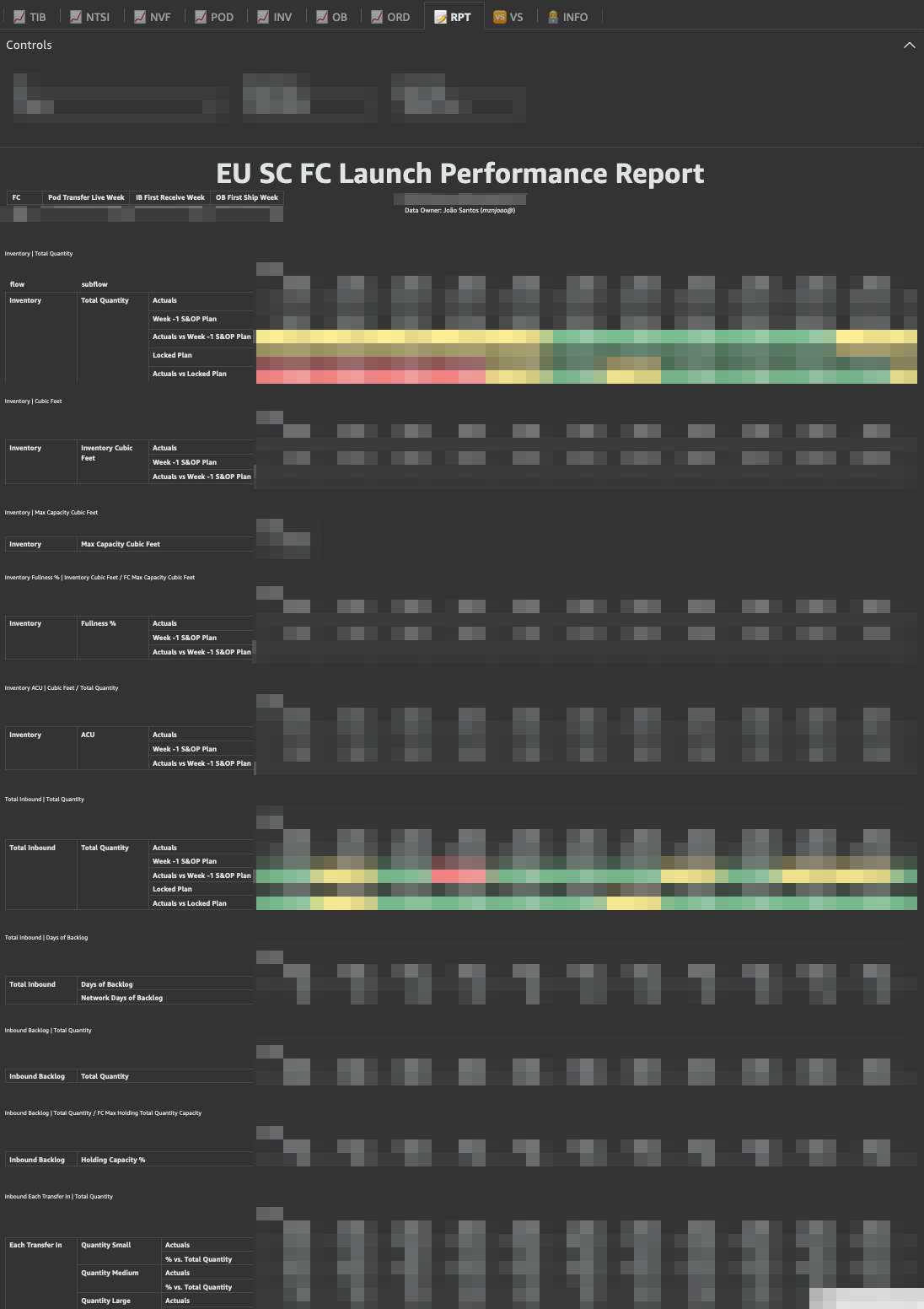
- EU SC FC Launch Performance QuickSight Dashboard
The EU SC FC Launch Performance Dashboard is a “One Stop Shop” metrics compilation to provide a user friendly interface and visualizations of new FC’s ramp up actuals vs. wk-1/locked S&OP plans.
Details
Internal Dashboard- It aims to not only support Launch PM with easy data access during pre/post launch period, but also facilitate post-mortem analysis such as comparing ramp up performance of FCs launched in different years;
- For each FC and Week combination there’re a different number of possible Flows and Subflows. For instance, as the main flow: Crossdock Transfer In, Inventory, Manual Transfer In, New Vendor Freight, New Workable Demand, Not Yet Received (FC Receive Correction), Orders Cancelled/ Confirmed/ Received/ Submitted, Pod Transfer In, Proactive Transfer In, Reactive Transfer In all have a respective subflow related to the total number of units drilled down by: Total Quantity, Quantity FBA and Quantity AMZN (Total Quantity = FBA + AMZN);
- The dashboard has 7 main metric tabs (📈 TIB, NTSI, NVF, POD, INV, NWD and ORD), a summary report tab (📝 RPT), an FC comparison tab (🆚 VS) and finally a tab dedicated to our team contact information and extract/ load job details (👨💻 INFO).
- Why Spread is Biased & How to Overcome it: Spread Bias
Development of a new metric: Spread Bias. A complementary metric to FC Spread (how many FCs on average an ASIN is sent to).
Details
Internal Documentation- Mathematically, it’s a weekly weighted average share of total volume cross-docked at each FC per ASIN. The more biased the volume is towards one particular FC, the more the spread bias will tend to 1. Reciprocally, the more evenly and the more FCs the volume is spread to, spread bias will tend towards 0;
- Spread Bias is [] x more correlated to deviations in Case Break than in FC Spread. Less Spread Bias leads to a more uniform FC level placement which, in turn, increases unique inventory and reduces the risk of TRB (constraint in outbound capacity);
- Semi-Automated Jupyter Notebook Code & Markdown paper with interactive .html python code preview and Plotly graphs, Placement Impact bridge with Pearson Correlation Analysis and SQL script for production use.
- ITS 2% Rule & Impact on Placement
Understanding of hard constrains in optimization models (SCOT heuristic approach to reduce latency of the request easing the algorithm decision time by removing the possibility of case break) and impact on placement and financial outcomes (spread, item selection, period 1/ period 2 AR share and misplacement volume).
Details
Internal Documentation- Expected a yearly decrease of 4MM units in total cross-border fulfillment (CBF) by reduction in misplaced volume, 3x more item selection leading to higher LIS, higher inventory turns and 2x less Spread Bias;
- Semi-Automated Jupyter Notebook Code & Markdown paper with interactive .html python code preview and interactive Plotly graphs.
- Tote Utilization Dashboard
Tote Utilization dashboard and monitoring for the IXD Sr. Ops Managers & Area Managers. Aimed at knowledge sharing and improved users tote filling best practices in order to increase truck fill rate and tote optimization.
Details
Internal Dashboard- Expected an increase of 2% in the weekly average tote utilization by IXD, leading to a yearly reduction of [] MM totes, 1k trucks, 800 tonnes of CO2 emissions and $ 1MM in overall savings;
- Data Pipeline between 2 AWS RedShift Clusters, Daily Maintenance of 6 Tables with SQL ETL Manager and AWS QuickSight.
- Arc Bin Level Forecast
Improved accuracy on the arc bin level forecast with univariate multi forecasting time series using Exponential Moving Average (EMA), Auto-ARIMA and FBProphet models.
Details
Internal Dashboard- QuickSight analysis and Dashboard for the preceding weekly arc bin volume and share;
- 5% increase in forecast accuracy leading to an expected optimization in bin level planning for bin fullness balance and IXD bin offsets;
- AWS SageMaker with Python: Pandas, Matplotlib, NumPy, Pmdarima and FBProphet, AWS RedShift and AWS QuickSight.
- Centralized Fluid Loading Dashboard
Centralized Fluid Loading (FL) Dashboard for the overall Productivity (fluid loading share, volume, fill rate and labor) Sustainability (saved number of trucks, CO2 emissions, plastic waste) and Savings (transportation, productivity gain, unloading cost) metrics.
Details
Internal Dashboard- EU IXD Fluid Loading is 100% more productive than normal pallet building and loading, loads 100% more items and reduces 50% of the trucks hence saving 13.5k tonnes of CO2 emissions;
- SQL Scheduled Extract Jobs and Microsoft Power BI: Waffle chart, Sankey diagram & Radar chart.
- Sort Share and Impact on Item Selection
Deep dive analysis regarding the impact on the unique item selection based on the IXD sort share deviation to ideals. Financial outcome based on the country level Cross-Border Fulfillment (CBF) cost on different ITS algorithm decisions.
Details
Internal Documentation- Improved sort share bridge to item selection and weekly WBR review in sort share deviation to ideals, right sortation and CBF due to wrong sortation;
- SQL Extract Jobs and Statistical Analysis with Excel: Pearson Correlation Coefficient, P-Value and Linear Regression.
Aimed at improving the Request Scheduling Efficiency by over 48% YoY.
Details
- Applied DMAIC methodology (Define, Measure, Analyze, Improve, and Control) as a data-driven improvement cycle to clearly articulate the business problem, goal, potential resources, project scope, and high-level project timeline;
- Implemented and Tracked KPIs with Python: Pandas, Statsmodels, Seaborn and Plotly;
- Semi-Automated a Relative Job Prioritization System with Excel: Power Query and VBA;
Ease the decision-making process associated with the control of the main chemical components concentrations and total organic contaminations (TOC).
Details
Public Documentation- Applying linear regression and correlation models (Pearson and Spearman) with R, Minitab and Excel;
- Implemented and Tracked KPIs with Python: Pandas, Statsmodels, Seaborn and Plotly;
- Extract, Transform and Load (ETL) process applied to past manufacturing datasets, implemented on the Business Intelligence and Analytics software platform Microsoft Power BI, retrieving valuable insights.
Certifications & MOOC
Projects